Automated Theorem Finding
|
|
Originally, these are schemes of axioms: each formula represents infinite family of axioms obtained by substitution of formulas for A, B, C. Here, these formulas are individual axioms.
3. Rules of inference
Common rules of inference are modus ponens and substitution.
Modus ponens or detachment. If F and (F → G) are theorems of propositional calculus, where F and G are propositional formulas then G is the theorem of propositional calculus. For instance, (A → A) and ((A → A) → (B → (A → A))) are theorems of propositional calculus. By modus ponens, the formula (B → (A → A)) is also theorem of propositional calculus. The formulas F and (F → G) are called premise minor and premise major respectively.
Substitution. If F is a theorem of propositional calculus, A1,..., An are variables and F1, ..., Fn are formulas of propositional calculus then formula F(F1/A1, ..., Fn/An) obtained by simultaneous substitution of F1 for A1, ..., Fn for An in F is also the theorem of propositional calculus. For instance, (A → A) is a theorem of propositional calculus; by substitution of (A → B) for A, the formula ((A → B) → (A → B)) is also theorem of propositional calculus.
Substitution can be applied on any theorem and used for derivation of infinitely many theorems. All theorems derived by substitution are less interesting than original one, however, they can be used in some application of modus ponens. Because of that, these two rules are integrated in one, more suitable for automated theorem finding.
Combined rule. If F and (G → H) are theorems of propositional calculus, where F, G and H are formulas of propositional calculus and there is a substitution u, such that u is unification of F and G, i.e. u(F) = u(G), then u(H) is also theorem of the propositional calculus. Without loss of generality it is required that u(H) is in canonic form, i.e. the variables occur in alphabetical order. For instance, the formula ((B → (A → B)) is not in canonic form and the formula ((A → (B → A)) is in canonic form.
4. Program 1.
The theorems of propositional calculus are derived sequentially.
- Theorems T1, T2, ..., T10 are axioms.
- Theorems T11, T12, ... are derived by single application of the combined rule on pairs of theorems (Ti, Tj), i, j = 1, 2, ... by order of Cantor's enumeration: (T1, T1), (T2, T1), (T2, T2), (T1, T2) ...
The algorithm is arguably the simplest possible algorithm for automated theorem finding in propositional calculus. It is complete: all theorems of the propositional calculus (in canonic form) will occur at some place in infinite sequence. It can be said even more: all theorems will occur infinitely many times in that sequence: if F is a theorem, then for every theorem G, formula (G → F) is also theorem and F can be derived from these two. However, duplicates can be simply omitted from the sequence of theorems.
The algorithm is implemented in newLISP dialect of Lisp. Propositional formulas are naturally represented as Lisp symbolic expressions and some frequently needed operations like unification, are supported.
The program is executed until first 100 000 theorems are derived. Application of the combined rule is attempted 1 127 490 times. Application of combined rule failed in 50% of attempts because premise major wasn't implication. In 34% of attempts unification of antecedent in premise major and premise minor wasn't possible. In 16% of attempts unification succeeded and conclusion is developed. In 7% of attempts, conclusion was already derived earlier during executions of the program. In 9% of all attempts, conclusion was previously unknown.
Following table contains the list of all theorems of the size (defined as number of operator and variable occurrences) five or less derived by program, with some related data.
| i | Ti | d(Ti) | |Ti| | |proof(Ti)| | ||proof(Ti)|| | c(Ti) | |
| 1 | 86 | (A → A) | 410 | 3 | 33 | 5 | 3.21 |
| 2 | 1 | (A → (B → A)) | 1679 | 5 | 5 | 1 | 1.38 |
| 3 | 3 | ((A and B) → A) | 1679 | 5 | 5 | 1 | 1.38 |
| 4 | 4 | ((A and B) → B) | 1679 | 5 | 5 | 1 | 1.38 |
| 5 | 6 | (A → (A or B)) | 1678 | 5 | 5 | 1 | 1.38 |
| 6 | 7 | (A → (B or A)) | 1678 | 5 | 5 | 1 | 1.38 |
| 7 | 10 | ((not (not A)) → A) | 1074 | 5 | 5 | 1 | 1.38 |
| 8 | 1190 | (not (A and (not A))) | 1 | 5 | 37 | 5 | 2.06 |
| 9 | 1210 | (not ((not A) and A)) | 1 | 5 | 37 | 5 | 2.06 |
| 10 | 2222 | (A → (A and A)) | 2 | 5 | 67 | 9 | 2.32 |
| 11 | 2230 | (A or (B → B)) | 1 | 5 | 43 | 7 | 2.12 |
| 12 | 2231 | ((A → A) or B) | 1 | 5 | 43 | 7 | 2.12 |
| 13 | 2234 | (A → (B → B)) | 3 | 5 | 43 | 7 | 2.12 |
The data in columns of the table are:
| i | ordinal number of derived theorem, | |
| Ti | theorem, | |
| d(Ti) | number of times the theorem is derived during execution of the program, | |
| |Ti| | size of the theorem, defined as number of operators and variables, | |
| |proof(Ti)| | size of the proof, defined as sum of the sizes of the theorems in proof, including derived theorem, | |
| ||proof(Ti)|| | number of steps in proof of the theorem (1 for axioms) and | |
| c(Ti) | coefficient defined with |Ti|c(Ti) = |proof(Ti)|. |
Coefficient c(Ti) is attempt for quantification of the intuition that interesting theorems are "deep" theorems, i.e. short theorems with long proofs.
For instance, the shortest theorem of propositional calculus, (A → A) is derived as 86. theorem; the proof is printed out in following form:
| tm-2. ((A → (B → C)) → ((A → B) → (A → C))), axiom
tm-1. (A → (B → A)), axiom tm-12. ((A → B) → (A → A)), M:tm-2, m:tm-1 tm-86. (A → A), M:tm-12, m:tm-11 |
Premise major and premise minor used in proving each steps are denoted with M and m respectively. Notation tm- is used for internal representation of theorem in program; for this particular algorithm, indexes are same. Original output of the program contains respective unifications as well.
Some disadvantages of the Program 1. are obvious. Some of derived theorems are instances of the already derived theorems. For example, theorem 89., ((A → B) → (A → B)) is an instance of the theorem 86. The algorithm doesn't prefer short theorems, although it appears that shorter theorems are of greater interest, from perspective of human reader and, perhaps, from computational complexity perspective.
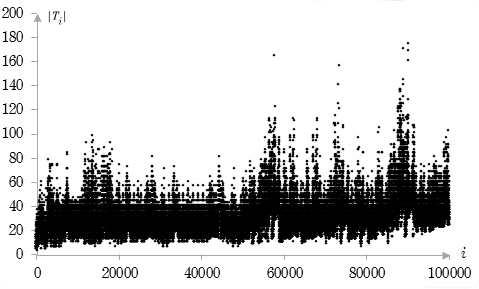
Fig 1. Size of the theorems derived by Program 1.
Attachments
- The program.
- Text file with 100 000 derived theorems and their proofs.
- CSV file with theorems and related data.
- CSV file with less important details on program execution.
5. Program 2.
Described algorithm can be improved by rejection of instances and addition of preference for a shorter theorems, i.e. standard "best first" strategy.
- Theorems T1, T2, ..., T10 are the axioms of propositional calculus.
- Theorem Tn+1 , for n = 10, 11, ... is the first theorem such that
- it can be derived by single application of the combined rule on pairs of theorems T1, T2, ..., Tn,
- it is not an instance of any of these theorems, and
- there is no shorter theorem satisfying conditions a. and b.
The program is developed in newLISP and executed for nearly two weeks on few years old personal computer. Application of the combined rule is attempted 10 000 000 001 times. It failed in 51% of attempts because premise major wasn't implication. In 23% of attempts unification of antecendent in premise major and premise minor wasn't possible. In 26% of attempts unification succeeded and conclusion is developed. In 13% of attempts, conclusion was too long to be added to the theory in any reasonable time; it is unknown how many duplicates were among these. Nearly 13% attempts resulted in duplication of already derived theorems. Finally, 0.0065% attempts were successeful and 0.001% attempts resulted with 100 001 shortest theorems.
Following table contains the list of all theorems of the size (defined as number of operator and variable occurences) less or equal to five, derived by program, with some related data.
| i | Ti | d(Ti) | |Ti| | |proof(Ti)| | ||proof(Ti)|| | c(Ti) | |
| 1 | 13 | (A → A) | 431576 | 3 | 33 | 5 | 3.207534 |
| 2 | 38384 | ((not A) or A) | 173362 | 4 | 468 | 57 | 4.651162 |
| 3 | 38385 | (A or (not A)) | 173362 | 4 | 416 | 51 | 4.516202 |
| 4 | 1 | (A → (B → A)) | 154928 | 5 | 5 | 1 | 1.37973 |
| 5 | 3 | ((A and B) → A) | 150188 | 5 | 5 | 1 | 1.37973 |
| 6 | 4 | ((A and B) → B) | 150188 | 5 | 5 | 1 | 1.37973 |
| 7 | 6 | (A → (A or B)) | 150630 | 5 | 5 | 1 | 1.37973 |
| 8 | 7 | (A → (B or A)) | 150630 | 5 | 5 | 1 | 1.37973 |
| 9 | 10 | ((not (not A)) → A) | 149718 | 5 | 5 | 1 | 1.37973 |
| 10 | 14 | (A or (B → B)) | 210089 | 5 | 43 | 7 | 2.121747 |
| 11 | 15 | ((A → A) or B) | 210089 | 5 | 43 | 7 | 2.121747 |
| 12 | 16 | (A → (B → B)) | 212851 | 5 | 43 | 7 | 2.121747 |
| 13 | 50 | (A → (A and A)) | 158696 | 5 | 67 | 9 | 2.318542 |
| 14 | 80 | ((A or A) → A) | 158513 | 5 | 93 | 13 | 2.475692 |
| 15 | 91 | (not (not (A → A))) | 204846 | 5 | 101 | 15 | 2.51689 |
| 16 | 708 | (not (A and (not A))) | 156264 | 5 | 37 | 5 | 2.058924 |
| 17 | 763 | (not ((not A) and A)) | 156284 | 5 | 37 | 5 | 2.058924 |
| 18 | 11142 | (A → (not (not A))) | 125517 | 5 | 214 | 27 | 2.92471 |
For instance, T38384, ((not A) or A) has the following proof, as printed out by program:
| tm-2. ((A → (B → C)) → ((A → B) → (A → C))), axiom tm-1. (A → (B → A)), axiom tm-11. (A → (B → (C → B))), M:tm-1, m:tm-1 tm-61. ((A → B) → (A → (C → B))), M:tm-2, m:tm-11 tm-10. ((not (not A)) → A), axiom tm-56. (A → ((not (not B)) → B)), M:tm-1, m:tm-10 tm-171. ((A → (not (not B))) → (A → B)), M:tm-2, m:tm-56 tm-3769. ((A → (not (not B))) → (C → (A → B))), M:tm-61, m:tm-171 tm-12. ((A → B) → (A → A)), M:tm-2, m:tm-1 tm-63. (A → A), M:tm-12, m:tm-1 tm-79. (((A → B) → A) → ((A → B) → B)), M:tm-2, m:tm-63 tm-80. (A → (B → B)), M:tm-1, m:tm-63 tm-20224. (((A → A) → B) → B), M:tm-79, m:tm-80 tm-20448. (A → (((B → B) → C) → C)), M:tm-1, m:tm-20224 tm-21078. ((A → ((B → B) → C)) → (A → C)), M:tm-2, m:tm-20448 tm-9. ((A → B) → ((A → (not B)) → (not A))), axiom tm-46593. (((not A) → A) → (not (not A))), M:tm-21078, m:tm-9 tm-47470. (A → (((not B) → B) → B)), M:tm-3769, m:tm-46593 tm-48685. ((A → ((not B) → B)) → (A → B)), M:tm-2, m:tm-47470 tm-7. (A → (B or A)), axiom tm-36. (A → (B → (C or B))), M:tm-1, m:tm-7 tm-157. ((A → B) → (A → (C or B))), M:tm-2, m:tm-36 tm-2963. ((not (not A)) → (B or A)), M:tm-157, m:tm-10 tm-3583. (A → ((not (not B)) → (C or B))), M:tm-1, m:tm-2963 tm-13238. ((A → (not (not B))) → (A → (C or B))), M:tm-2, m:tm-3583 tm-58849. (((not (A or B)) → (not (not B))) → (A or B)), M:tm-48685, m:tm-13238 tm-6. (A → (A or B)), axiom tm-46. ((A → (not (A or B))) → (not A)), M:tm-9, m:tm-6 tm-780. (A → ((B → (not (B or C))) → (not B))), M:tm-1, m:tm-46 tm-23987. ((A → (B → (not (B or C)))) → (A → (not B))), M:tm-2, m:tm-780 tm-203206. ((not (A or B)) → (not A)), M:tm-23987, m:tm-1 tm-203408. ((not A) or A), M:tm-58849, m:tm-203206 |
Notation tm- stands for internal representation of theorems in program. For instance, T38384 is tm-203408.
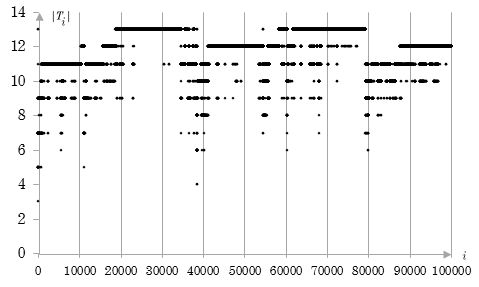
Fig 2. Size of the theorems derived by Program 2.
The graph shows that derived theorems are much shorter than those derived with Program 1. It is clearly visible which theorems are relatively short, yet they are derived relatively lately. Theorems T38384 and T38385, for instance, are among these. Some short theorems are used in futher derivation of short theorems. It is seen on graph as dent in graph; for instance, between T38383 and T54482. The width, depth and area of the dent suggest the importance of the theorem a posteriori. It appears that there is a correlation with size of proof as measure of the importance of theorem a priori.
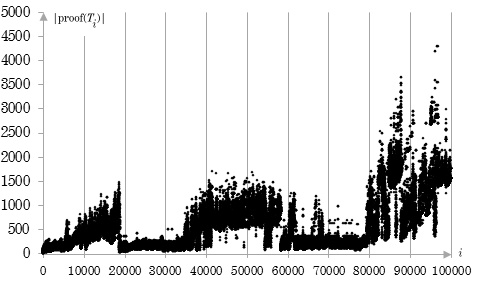
Fig. 3. Size of the proofs of theorems derived by Program 2.
A few weaknesses of Program 2. are obvious. Although derived theorems are not instances of a previously derived theorems, human can recognize that many of these theorems are weak. For instance, theorems containing double negation; theorems of the form (F or G), where at least one of the formulas F and G is a theorem; theorems with subformulas of the form (F or F), (F and F), where F is any formula; thorems that could be obtained by application of commutativity and associativity of operations or and and and so forth.
Attachments
- The program.
- Text file with 100 001 derived theorem and their proofs.
- CSV file with theorems and related data.
- CSV file with less important details on program execution.
6. Conclusion
The program should be extended to reject more trivial variations of already derived theorems, as humans do. The results obtained so far appear to be interesting enough to justify further experiments.
References
- Colton, S. and Bundy, A., "On the Notion of Interestingness in Automated Mathematical Discovery" in Proceedings of the AISB'99 Symposium on AI and Scientific Discovery, Edinburgh, UK, 1999.
- Mendelson, E., Introduction to Mathematical Logic, many editions.
- Poincare, H., Science and Method, Dover Publications, Mineola, 2003.
- Wang, H., Toward Mechanical Mathematics, IBM Journal of Research and Development, Vol. 4 No. 1, January 1960, pp. 2-22.
- Wang, H., Survey of Mathematical Logic, Nort Holland, Amsterdam, 1963.
- Wos, L., Automated Reasoning: 33 Basic Research Problem, Prentice-Hall, 1988.
- Wos, L., The Problem of Automated Theorem Finding, Journal of Automated Reasoning, Vol. 10 No. 1, 1993, pp. 137-8.